

Migrations at Aquanode across VMs
So i am training a translation model for a low-resource akkadain language. But using a single gpu whole time, doesn't make sense.
TLDR
- Used A100 for data processing
- Used 5090 for training
- Resumed training on another VM
- Uploading Final Weights to HuggingFace on my repo
Data Processing on A100
I needed to do some quality translations on my data, hence using Qwen/Qwen3-30B-A3B-Instruct-2507
I will just have migrations on my data directory: /root/data
I processed my stuff.
Took manual snapshot, and closing the instance.
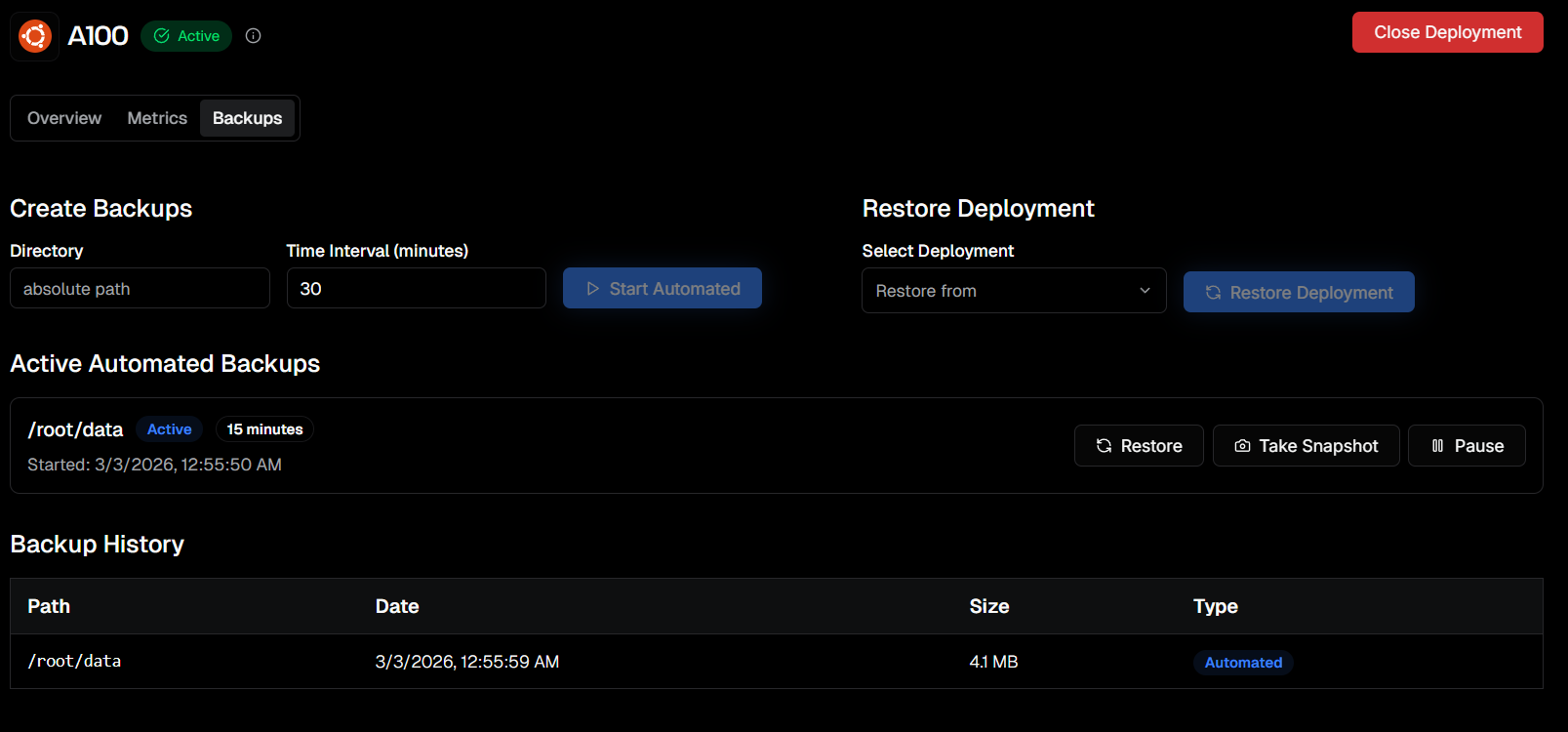
My training can happen on 5090, so i will continue it there.
To get the processed data here, just get the migrations. All data available on same path /root/data
Now let's start training.
Training
Sometimes your shell may exit or ssh connection drops, that can kill the process associated with shell.
Using tmux to create a persistent process, so we can detah from shell
tmux new -s train
source .venv/bin/activate
python train.py --lr 1e-4 --batch_size 4
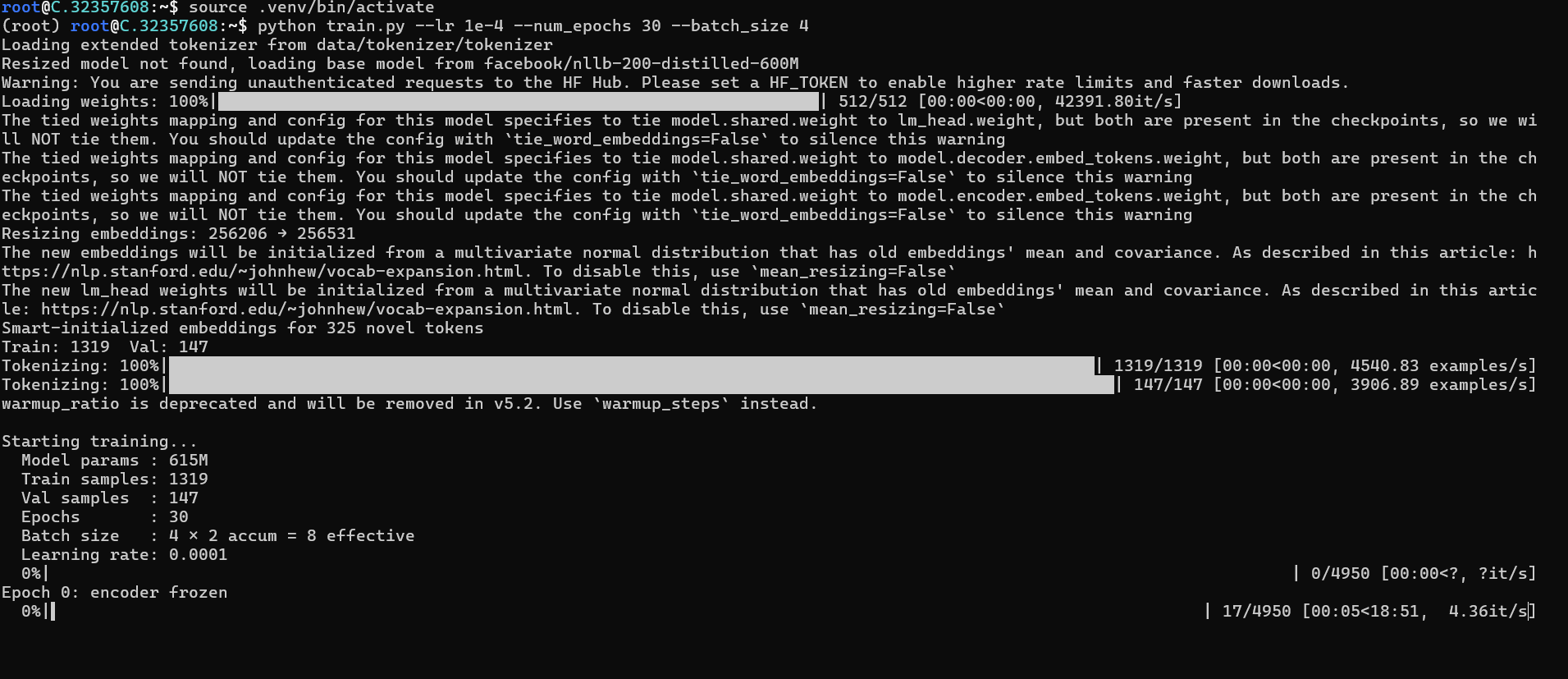
Ctrl + B, then D (to detach, doesn't kill the process, now you can safely exit)
tmux attach -t train
Mean time, let's invoke migrations for /root choose time based on how long this training will go for.
After the desired training is done, or even if closed
Here now after getting things done, i closed my VM.
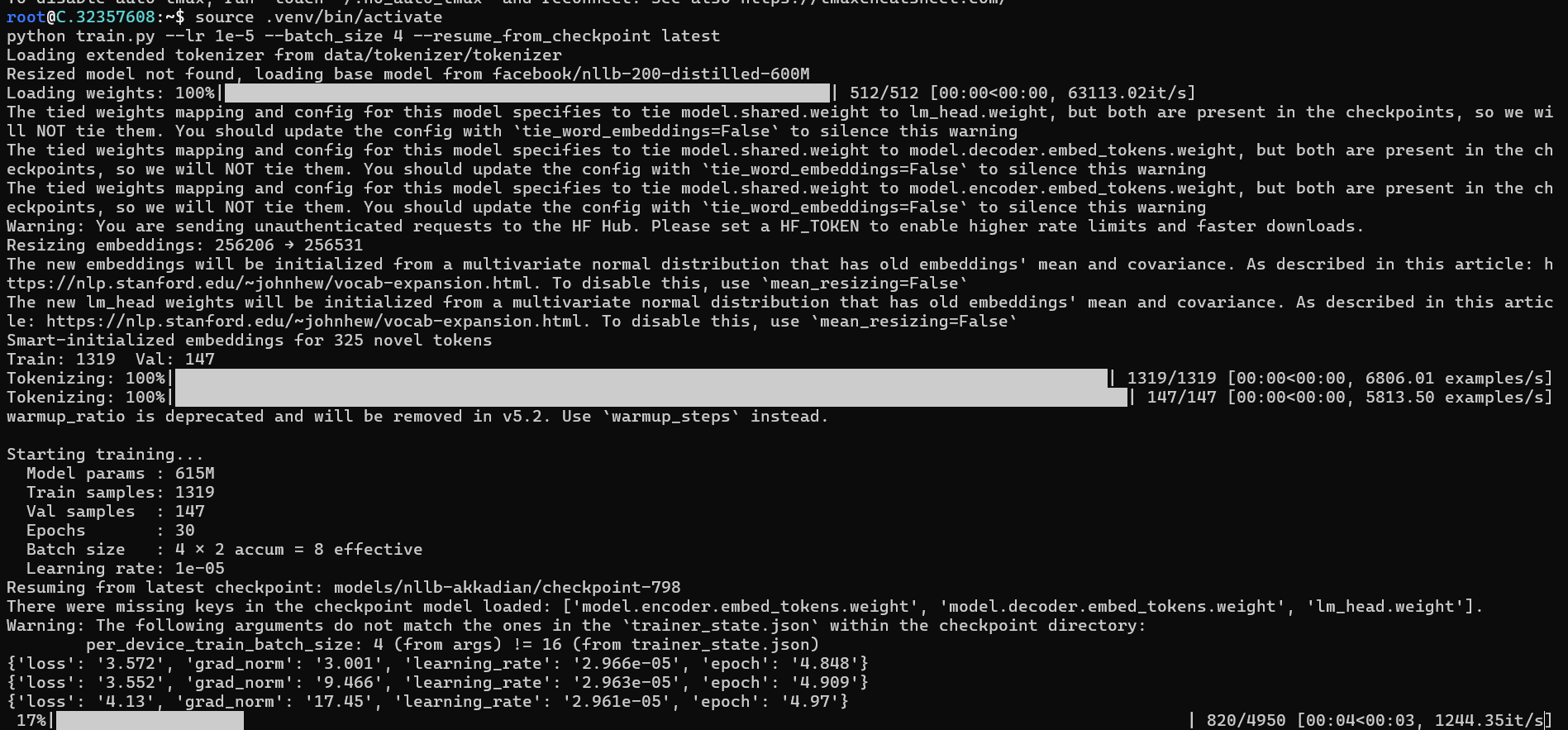
And now let's resume our training
Resume Training
Get the migrations for the last snapshot.
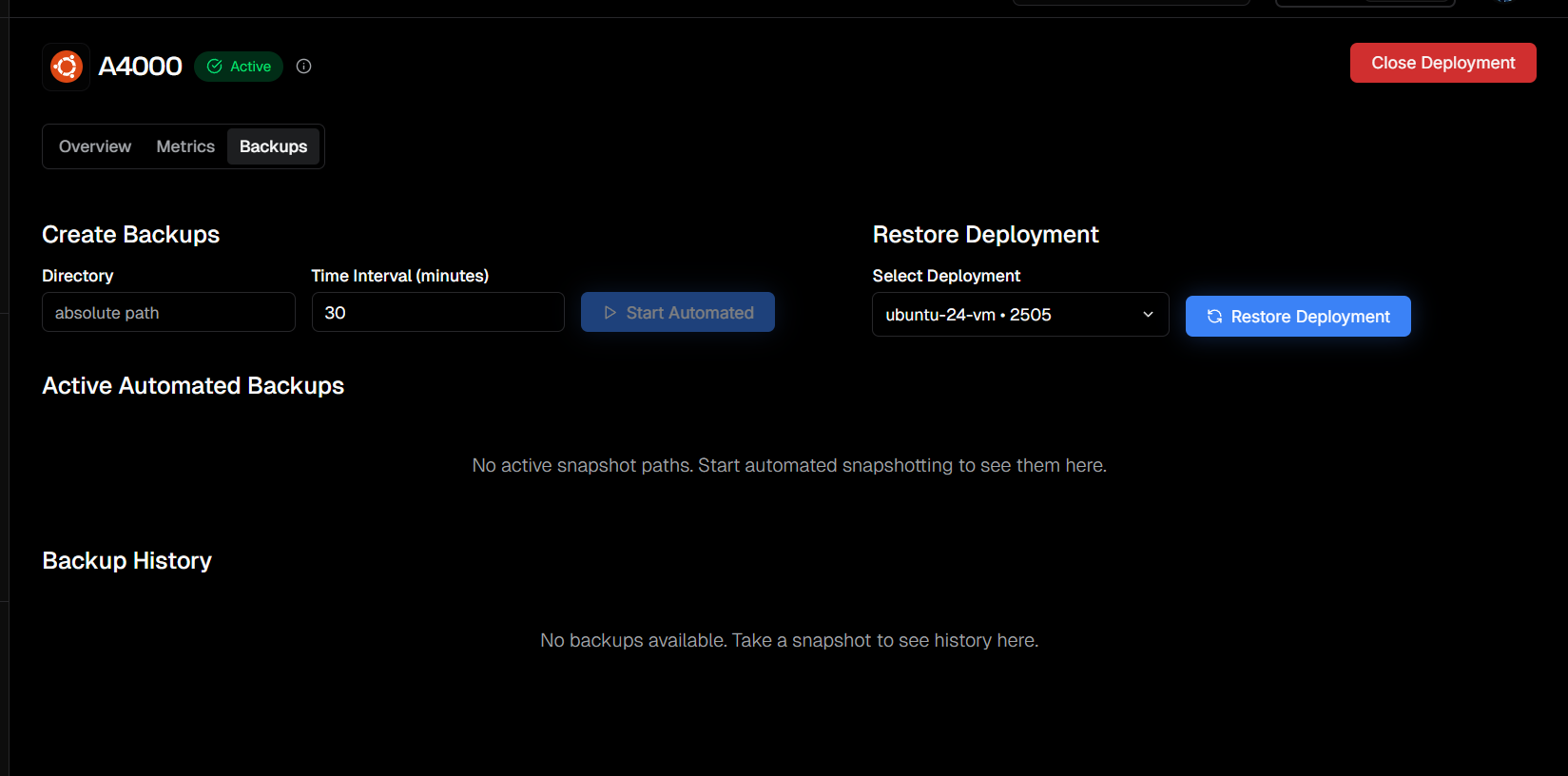
It took 5 minutes for the 33GB of Data.
Acivate venv
tmux new -s train
source .venv/bin/activate
python train.py --lr 1e-5 --batch_size 4 --resume_from_checkpoint latest
Uploading model to HuggingFace
hf auth login
hf upload <user-name/repo> <path to upload from>
hf upload Arpit-Bansal/Akkadian-experiments models/